當(dāng)前位置:
首頁(yè)
>
產(chǎn)品大全
>
實(shí)驗(yàn)1 數(shù)據(jù)獲取、存儲(chǔ)與預(yù)處理——從網(wǎng)頁(yè)爬蟲(chóng)到數(shù)據(jù)服務(wù)的完整通路
實(shí)驗(yàn)1 數(shù)據(jù)獲取、存儲(chǔ)與預(yù)處理——從網(wǎng)頁(yè)爬蟲(chóng)到數(shù)據(jù)服務(wù)的完整通路
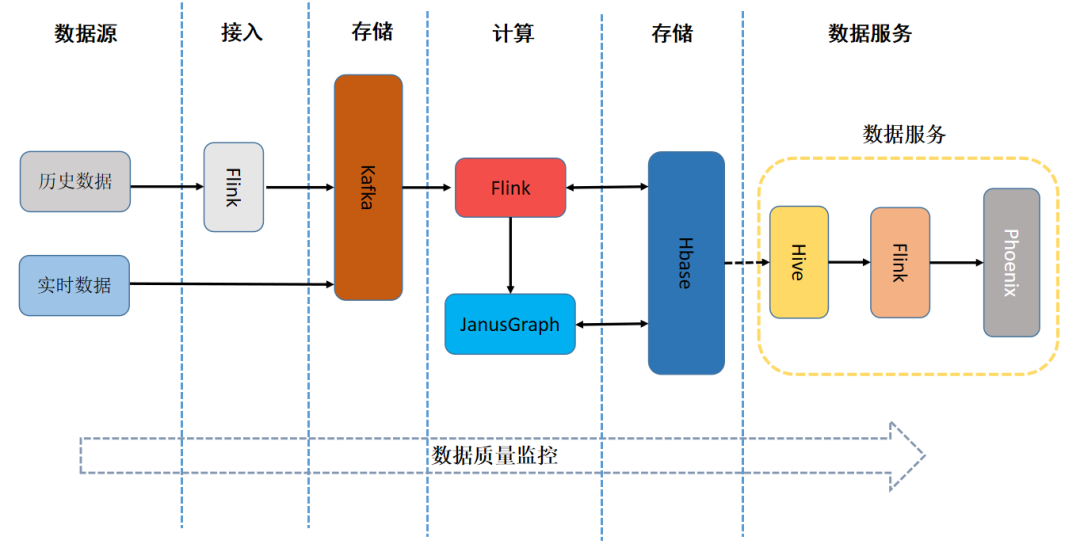
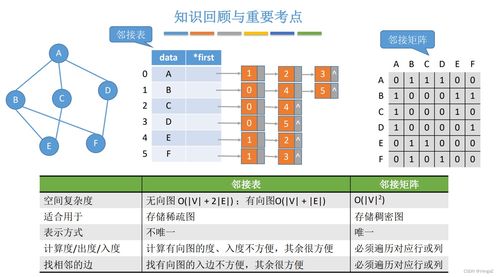
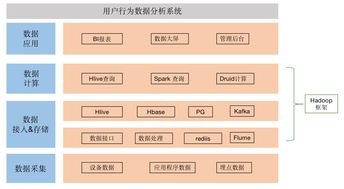
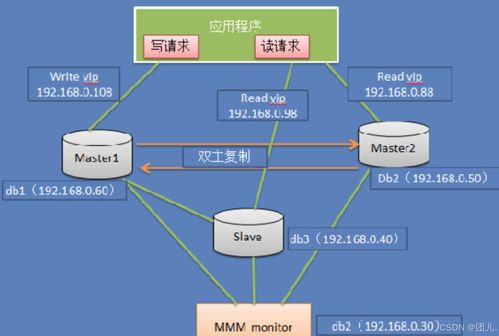
實(shí)驗(yàn)1:數(shù)據(jù)獲取、存儲(chǔ)與預(yù)處理\n\n## 摘要\n本實(shí)驗(yàn)圍繞網(wǎng)絡(luò)數(shù)據(jù)的全生命周期處理,通過(guò)一個(gè)實(shí)用案例,說(shuō)明了網(wǎng)頁(yè)爬蟲(chóng)構(gòu)建、數(shù)據(jù)解析、數(shù)據(jù)庫(kù)存儲(chǔ)以及基礎(chǔ)預(yù)處理的方法。實(shí)驗(yàn)旨在掌握自動(dòng)化獲取公開(kāi)網(wǎng)絡(luò)數(shù)據(jù)、結(jié)構(gòu)化信息提取、數(shù)據(jù)持久化存儲(chǔ)及臟數(shù)據(jù)清洗等關(guān)鍵技術(shù)和思想。\n\n## 一、實(shí)驗(yàn)?zāi)康腬n1. 熟悉Python中的Urllib/Requests庫(kù)及Scrapy框架構(gòu)建簡(jiǎn)單的網(wǎng)頁(yè)爬蟲(chóng);\n2. 掌握正規(guī)表達(dá)式與BeautifulSoup進(jìn)行數(shù)據(jù)解析的工具;\n3. 能夠連接MySQL或SQLite數(shù)據(jù)庫(kù)存儲(chǔ)結(jié)構(gòu)化數(shù)據(jù);\n4. 配合Pandas完成基本數(shù)據(jù)預(yù)處理(缺失值移除、去重、文本規(guī)整),建立一條清洗到服務(wù)的概覽流程。\n\n## 二、技術(shù)路線\n使用開(kāi)源數(shù)據(jù)集網(wǎng)絡(luò)(如GitHub開(kāi)源列表、天氣查詢或蘑菇分類(lèi)樣例站),基本設(shè)計(jì)如下:\n
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.santachair.com/product/85.html
更新時(shí)間:2026-06-18 18:29:55